If you already had a look at the YapiBot source code and are familiar with multi-threaded application, you probably noticed that while the code is thread safe, I did not take any care to enforce in which context function call is made. For example, when receiving a message on the command socket, all the action resulting from this message will be done in the context of the socket thread. It’s not a big deal here because the project is still small but that might be an issue for bigger projects as it might be dangerous and may cause deadlocks. It is also difficult to control the priority of execution and might be an issue in projects having tight real time constrains.
A common design pattern to enforce the context of execution is the Active class. It’s a class which has its own execution thread and every action is going to executed in that context.
We usually differentiate two kind of method invocation to an active class.
Asynchronous call: They are fire & forget calls. Caller has no information on when the call is completed. That implies that it is not possible to have a return value.
Synchronous call: Caller needs to get a notification that the call is complete. A return value is possible but not mandatory.
A third method is also sometimes possible and somewhere in the middle: Call is asynchronous until we need to get the returned value then it waits until the value is available.
There is many active class implementation available but It was a very good exercise for me to have a looks at the possibilities of C++11 in particular the thread support functionalities. My design goal will be, by using as many as possible c++11 feature to build a base class which can be inherited from with the fewer code possible. It also needs to be as seamless as possible for the caller.
I’m going to present several steps going more and more generic which will allows me to introduce the concepts. If you are familiar with C++11 and Actives class you can just jump to the step 3 to check the result. Source code is available at the end of the post.
Step 1: Basic deferred call
#include <iostream>
#include <future>
#include <thread>
#include <chrono>
class CActiveClass
{
public:
CActiveClass () {};
~CActiveClass () {};
private:
void privAsyncMethod (void) {
std::this_thread::sleep_for(std::chrono::seconds(2));
std::thread::id this_id = std::this_thread::get_id();
std::cout << "privAsyncMethod called in " << this_id << " context\n";
}
int privSyncMethod (void) {
std::this_thread::sleep_for(std::chrono::seconds(1));
std::thread::id this_id = std::this_thread::get_id();
std::cout << "privSyncMethod called in " << this_id << " context\n";
return 42;
}
public:
void pubAsyncMethod (void) {
std::async(std::launch::async, std::bind (&CActiveClass::privAsyncMethod, this));
}
int pubSyncMethod (void) {
auto ret = std::async(std::launch::async, std::bind (&CActiveClass::privSyncMethod, this));
return ret.get();
}
};
int main ()
{
std::thread::id this_id = std::this_thread::get_id();
std::cout << "Main running in " << this_id << " context\n";
CActiveClass active;
std::cout << "calling async method from main\n";
active.pubAsyncMethod();
std::cout << "calling sync method from main\n";
int ret = active.pubSyncMethod ();
std::cout << "Synccall returned " << ret << "\n";
return 0;
}
Our class has a public interface but all the real work is done inside the private methods. To go from one context to another we use here std::async which will launch a thread to execute the function passed as the argument. As the function is a class method we have to used std::bind which is a kind of a magic function which allows us to “package” our instance with the method call (we will see later that it can be used to bind call argument too).
The return value of std::async is an std::future which is a very nice new feature of c++11. A std::future is a value which may not be yet available. It is associated with a std::promise where the value will be posted when it is ready. You can see it as a single usage mailbox. So it is possible to get a future from a function call even if the result is not computed yet and keep going until we need to use it. Then get() will return the value, or block until it is ready. On the other side, the result is simply posted to the associated std::promise when it is available. That’s a very easy way to synchronise two threads while taking the full advantage of a distributed or multi CPU system.
So is that it ? Unfortunately no, even if our function call are deferred to another thread, it is not our class own thread and we have no way to control in which thread the execution will take place. In fact the execution can be deferred to any thread from a pool. So clearly that’s not an active class as we want it.
Also, running this give the following output:
>lythaniel@lythaniel-VirtualBox:~/ActiveClass/build$ ./ActiveClass
>Main running in 3073943296 context
>calling async method from main
>privAsyncMethod called in 3073936192 context
>calling sync method from main
>privSyncMethod called in 3073936192 context
>Synccall returned 42
In the case of the synchronous call, the output is as expected but for the asynchronous call it is not. As the privAsyncMethod takes a long time to run we shall be calling pubSyncMethod before the async call is complete. In fact, there is small pitfall here while using std::async. This function returns a future even if you don’t use it. And this future is a little bit special because it will wait for the promise to be posted when the destructor is called. Even if it is not visible in the code, this future still exists and is deleted right after the std::async invocation turning our async function into a synchronous one.
Step 2: Controling the execution context.
We saw that using std::async as a way to defer our execution to another thread was not a practical solution in this case. So we will have to spawn our own thread and use it to execute the task. Basic principle is, caller push the job into a fifo, it wakes up the processThread which in return fetchs the job from the fifo and executes it in the correct context, eventually, the result needs to be passed back to the caller. Sounds easy, but it faces an issue: every method may have a different return and argument type so it is difficult to store them and to execute them without having the knowledge of the function. That’s why the job will be packed into an polymorphic class. A pure abstract base class will only have a pure virtual execute method and we will have a class for each of the method type to call. Of course using template we won’t need to write one for each method . Fifo will store pointers to base class and the process thread just has to execute them without worrying about what’s going on behind.
class CTaskBase {
public:
virtual void execute (void) = 0;
};
template <class C, class Ret>
class CTask : public CTaskBase
{
public:
typedef Ret (C::*Method)(void);
CTask (C* ptr,Method method) :
m_Task(std::bind(method, ptr))
{
}
~CTask () {}
std::future<Ret> get_future (void)
{
return m_Task.get_future();
}
virtual void execute (void)
{
m_Task();
}
private :
std::packaged_task< Ret (void)> m_Task;
};
To store the function call, we will use another neat feature of C++11: std::packaged_task. Push a function in it with arguments if needed (using std::bind), call it later and get the result via a future. That’s nearly all we need here but as packaged_task is specialized for a type, we still need to have an abstraction.
void CActiveclass::taskLoop (void) {
CTaskBase * task = NULL;
std::thread::id this_id = std::this_thread::get_id();
std::cout << "CActiveClass processLoop started in " << this_id << " context\n";
while (m_Delete.load() == false)
{
std::unique_lock<std::mutex> uniqueLock(m_CondMutex);
m_Cond.wait(uniqueLock, [this]{return m_TaskInQueue.load();});
uniqueLock.unlock();
do {
m_TaskQueueMtx.lock();
if (!m_TaskQueue.empty())
{
task = m_TaskQueue.front();
m_TaskQueue.pop();
}
else
{
task = NULL;
m_TaskInQueue.store(false);
}
m_TaskQueueMtx.unlock();
if (task != NULL)
{
task->execute ();
delete task;
}
} while (task != NULL);
}
}
I used a std::condition_variable as the wake up source for the task which is a little bit of overkill in that case as a semaphore could have done the job just as well, but it is a way to show it’s usage and it might be usefull if we want to add additionnal wake up source later.
Our public method now look like this:
int pubSyncMethod (void) {
CTask<CActiveClass, int> * task = new CTask<CActiveClass, int> (this,&CActiveClass::privSyncMethod);
auto ret = task->get_future();
{
std::lock_guard<std::mutex> lg (m_TaskQueueMtx);
m_TaskQueue.push(task);
}
{
std::lock_guard<std::mutex> lg (m_CondMutex);
m_TaskInQueue.store(true);
m_Cond.notify_one();
}
return ret.get();
}
void pubAsyncMethod (void) {
CTask<CActiveClass> * task = new CTask<CActiveClass> (this,&CActiveClass::privAsyncMethod);
{
std::lock_guard<std::mutex> lg (m_TaskQueueMtx);
m_TaskQueue.push(task);
}
{
std::lock_guard<std::mutex> lg (m_CondMutex);
m_TaskInQueue.store(true);
m_Cond.notify_one();
}
}
Runing the application we get:
>lythaniel@lythaniel-VirtualBox:~/ActiveClass/build$ ./ActiveClass
>Main running in 3074123520 context
>calling async method from main
>calling sync method from main
>CActiveClass processLoop started in 3074116416 context
>privAsyncMethod called in 3074116416 context
>privSyncMethod called in 3074116416 context
>Synctask returned 42
As expected, calling the async method is not blocking anymore and all the private method are called into the correct context.
Step 3: Making it generic.
So now that the basic is working, we have to make it generic. Remember, we want to be able to easly create any active class by just inheriting from the base class and to add our own method with a minimum of code.
Templates are going to be a great help here because they will remove the need to add code for every type of method but prior to c++11, you needed to write a template for every number of argument you needed. So you had to limit the maximum number of arguments possible and then write a template for each. Not a big deal but kind of dull work when you need to support a great number of argument. Hopefully, c++11 brings a new feature: variadic templates. Just like variadic arguments which handle “any number of arguments”, variadic template means “any number of argument types” (which can be none). it looks like this:
template <typename... Args>
void foobar (Args... args) {}
Ctask is modified accordingly and two function AsyncWrapper and SyncWrapper has been added to create them and push them into the task queue. A new wrapper is also available which return a future instead of the value itself so we can have the possibility to start a task and use the result later.
You can see that i’m now using std::bind to bind the class instance and the method together but also the arguments.
#include <iostream>
#include <future>
#include <thread>
#include <chrono>
#include <mutex>
#include <condition_variable>
#include <queue>
#include <cassert>
template <class C>
class CActiveClass
{
public:
CActiveClass () :
m_Delete (false), //Order is important.
m_TaskThread(std::bind(&CActiveClass::taskLoop, this)) {}
~CActiveClass ()
{
m_Delete.store (true);
{
//Unblock the thread.
std::lock_guard<std::mutex> lg (m_CondMutex);
m_TaskInQueue.store(true);
m_Cond.notify_one();
}
//Wait for the thread to finish
m_TaskThread.join();
//Assert in case the call queue is not empty.
assert (m_TaskQueue.empty()) ;
}
private:
class CTaskBase {
public:
virtual void execute (void) = 0;
};
template <typename Ret, typename... Args>
class CTask : public CTaskBase
{
public:
typedef Ret (C::*Method)(Args...);
CTask (C* ptr,Method method, Args... args) :
m_Task(std::bind(method, ptr, args...))
{
}
~CTask () {}
std::future<Ret> get_future (void)
{
return m_Task.get_future();
}
virtual void execute (void)
{
m_Task();
}
private :
std::packaged_task<Ret ()> m_Task;
};
void taskLoop (void) {
CTaskBase * task = NULL;
while (m_Delete.load() == false)
{
//Wait for task to be run.
std::unique_lock<std::mutex> uniqueLock(m_CondMutex);
m_Cond.wait(uniqueLock, [this]{return m_TaskInQueue.load();});
m_TaskInQueue.store(false);
uniqueLock.unlock();
do {
task = NULL;
m_TaskQueueMtx.lock();
if (!m_TaskQueue.empty())
{
task = m_TaskQueue.front();
m_TaskQueue.pop();
}
m_TaskQueueMtx.unlock();
if (task != NULL)
{
task->execute ();
delete task;
}
} while (task != NULL);
}
}
protected:
template <typename... Args>
void AsyncWrapper (C* pMe, void (C::*method)(Args...), Args... args)
{
assert (!m_Delete.load());
CTask< void, Args...> * task = new CTask< void, Args...> (pMe, method, args...);
{
std::lock_guard<std::mutex> lg (m_TaskQueueMtx);
m_TaskQueue.push(task);
}
{
std::lock_guard<std::mutex> lg (m_CondMutex);
m_TaskInQueue.store(true);
m_Cond.notify_one();
}
}
template <typename Ret, typename... Args>
Ret SyncWrapper (C* pMe, Ret (C::*method)(Args...), Args... args) {
assert (!m_Delete.load());
CTask<Ret, Args...> * task = new CTask< Ret, Args...> (pMe, method, args...);
auto ret = task->get_future();
{
std::lock_guard<std::mutex> lg (m_TaskQueueMtx); //Lock is released when lg is destroyed
m_TaskQueue.push(task);
}
{
std::lock_guard<std::mutex> lg (m_CondMutex); //Lock is released when lg is destroyed
m_TaskInQueue.store(true);
m_Cond.notify_one();
}
return ret.get();
}
template <typename Ret, typename... Args>
std::future<Ret> FutureWrapper (C* pMe, Ret (C::*method)(Args...), Args... args) {
assert (!m_Delete.load());
CTask<Ret, Args...> * task = new CTask< Ret, Args...> (pMe, method, args...);
std::future<Ret> ret = task->get_future();
{
std::lock_guard<std::mutex> lg (m_TaskQueueMtx); //Lock is released when lg is destroyed
m_TaskQueue.push(task);
}
{
std::lock_guard<std::mutex> lg (m_CondMutex); //Lock is released when lg is destroyed
m_TaskInQueue.store(true);
m_Cond.notify_one();
}
return ret;
}
private:
std::atomic<bool> m_Delete; //Order is important.
typedef std::queue <CTaskBase> taskQueue_t;
taskQueue_t m_TaskQueue;
std::mutex m_TaskQueueMtx; //stl is not thread safe, we need to protect the queue.
std::atomic<bool> m_TaskInQueue; //A little bit overkill for a boolean which is likely already atomic.
std::thread m_TaskThread;
std::mutex m_CondMutex;
std::condition_variable m_Cond;
};
Using this base class to build an Active class can then easly be done.
#include "ActiveClass.h"
class CMyActiveClass : public CActiveClass<CMyActiveClass>
{
public:
CMyActiveClass() {};
~CMyActiveClass() {};
int syncMultiply (int a, int b)
{
return SyncWrapper<int, int, int>(this, &CMyActiveClass::privMultiply, a, b);
}
void asyncSayHello (void)
{
AsyncWrapper<>(this, &CMyActiveClass::privSayHello);
}
std::future<float> futureDivide (float x, float y)
{
return FutureWrapper<float, float, float>(this, &CMyActiveClass::privDivide, x, y);
}
private:
int privMultiply (int a, int b)
{
return a * b;
}
void privSayHello (void)
{
std::cout << "Hello world !\n";
}
float privDivide (float x, float y)
{
std::this_thread::sleep_for(std::chrono::milliseconds(1000)); //That's a very long operation ...
return x/y;
}
};
Conclusion:
The active class presented here “do the job” but could use some improvement. constructor & destructor are potentially dangerous as the base class will be constructed before and destroyed after the herited class. This means that the task loop will be running while the herited class does not exist which can be an issue. Also I beleive that it could be improved by adding a notion of priority of the task, maybe based on the caller thread priority (for RT systems).
This was however a great show case of the possibility of c++11 and I was surprised & pleased to see how it made the building of such class easy and portable.
Source code under MIT licence: ActiveClass.tar





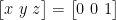
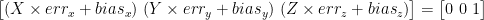
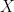 ,
, 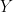 , and
, and 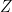 are the measurement done on the according axes,
are the measurement done on the according axes,  is the scalling error and
is the scalling error and  is the offset error.
is the offset error.





 it can be shown that
it can be shown that  can be left multiply by the inverse of its jacobian matrix.
can be left multiply by the inverse of its jacobian matrix.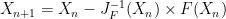


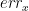 ,
,  ,
, 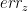 ,
,  ,
,  , and
, and  .
. on
on  we get:
we get:
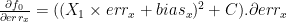

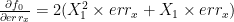
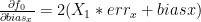
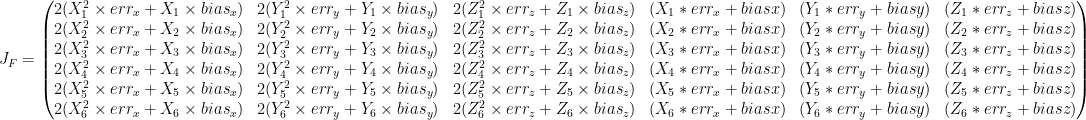

 as the unknown.
as the unknown. which is “easy” to solve using a
which is “easy” to solve using a